Why Neural Networks Fail on Constraints and why Lagrangian Geometry works better
Neural networks are extremely good at learning patterns, but they struggle when the problem demands obedience rather than approximation. In particular, they often fail when outputs must satisfy strict rules, conservation laws, geometric consistency, physical constraints and sometimes even logical structure.
This failure is not a matter of insufficient data or model size. It is geometric. In this article, I argue that hard-constraint problems define lower-dimensional geometric objects inside high-dimensional spaces, and that standard neural network training does not naturally respect these objects. By viewing constraints through the lens of geometry, I believe we can gain a clearer understanding on how to tackle these problems.
What is a constraint and what should classify as one?
A constraint is simply a rule that says that not everything is allowed. You can think of it as a fence that blocks a wall. Operating inside the wall is very permissible, but outside of it is invalid. So a constraint limits what is required as input or output depending on the nature.
Formally, we define the following.
Let be the input space and be the output space.
A model (neural network) is defined as:
A constraint is a condition that restricts the set of admissible outputs.
Formally, a constraint is a function:
with feasibility conditions such as:
Equality constraint:
Inequality constraint:
These constraints define the feasible set:
Any output is considered invalid if:
What should classify as a constraint?
Basically, anything that restricts a space can be classified as a constraint. But this raises an important question: how do we identify a constraint mathematically?
It turns out that identifying constraints is much easier than it first appears. The key idea is simple: a constraint is anything that removes degrees of freedom from a space. In other words, it shrinks the set of allowable configurations.
Mathematically, this happens whenever we impose a condition that restricts a space to a smaller subset This restriction may take the form of equations, inequalities, or structural rules, but the effect is always the same: not every point in the original space is allowed.
Examples of constraints would include algebraic manifolds and normalization conditions. My argument is that the root cause is geometric: standard neural training optimizes in parameter space, while constraints live on manifolds in output space.
Modern neural networks are universal function approximators, yet universality does not imply constraint satisfaction. It actually turns out that models trained with standard empirical risk minimization frequently violates a number of constraints like physical conservation laws, Normalization constraints and even algebraic invariant.
One of the ways that is used to solve this is by adding a penalty term to the loss function. Surprisingly, we can only get something good using excessively large penalty coefficients.
Learning with Hard Constraints.
Let us take a look at a classical problem involving learning with hard constraints.
Let a neural network be defined as
with parameters Suppose the output must satisfy a hard constraint
where
The learning objective becomes a constrained optimization problem:
The feasible outputs lie on a manifold
What is a manifold?
A manifold is a curved surface that looks flat when zoomed in on it. Think of the earth. From an outer viewpoint, the earth is spherical and curved; but inside of the sphere appears to be locally flat. We say that a manifold is thus a curved surface that is locally Euclidean. More subtly, a manifold appears whenever constraints reduce freedom without destroying smoothness.
Informal definition
An n-dimensional manifold is a space that, around every point, looks like ordinary
Formally:
A topological space is an n-dimensional (smooth) manifold if for every point , there exists:
-
An open neighborhood containing p
-
A map (called a chart)
such that:
- is bijective
- is continuous
- is continuous
This means:
Smooth manifolds
A manifold is smooth if whenever two charts of the manifold overlap, their transition map is smooth.
Let
Then the map
must be infinitely differentiable
Embedded (constraint-defined) manifolds
Now let us define manifolds in the sense of constraints, which is the essence of this article. Before I put out the mathematics, let us try to get the idea behind constraint-defined manifolds.
Imagine you've got a huge playground. You're allowed to move around anywhere on the playground unrestricted. Now assume that a teacher marks a tape around the playground. The tape twists and turns and creates varying paths on the playground. The teacher says you're not allowed to move beyond the paths marked by the tape. This means that you're now constrained by the tape.
The tape is the rule that you must follow (the constraint) Despite shifting and turning, each path on the tape feels locally flat. The track created by the tape is the manifold and it lives inside the playground. Now we can formally define the constraint-defined manifold.
Let:
Define:
If:
- c is smooth
- The Jacobian has full rank k on
Then is a smooth manifold of dimension
The penalty Method
Let us go back a bit to our playground analogy. Now put a baby in the playground and ask him to follow these rules. Definitely the baby has no idea what the rule is and is used to moving around freely in the open playground space. To constrain the baby, you introduce murky sand or muddy water on the other parts outside the tape. The is still allowed to move freely, but when he gets outside the tape, he is stuck in muddy water and requires a lot more energy to push through. Gradually after multiple punishment, the baby learns to stay within the taped path. This is exactly what the penalty method does. To constrain the neural network (NN), we introduce a penalty term. The penalty term relaxes the constraint to give meaningful outcomes.
As , optimization theory suggests convergence to the constrained solution. However, neural networks slightly violate these assumptions under which this guarantee holds.
Now in practice, using very large may work but at what cost? Well, empirically, increasing often causes gradient domination by the penalty term, optimization instability and poor convergence to feasible solutions.
"Penalty methods can approximate the constraint by making large, achieving violations on the order of to . However, this comes at severe costs: gradients become unstable with spikes exceeding , training slows dramatically, and exact constraint satisfaction (violation = 0) is never achieved. As , the optimization problem becomes ill-conditioned. For applications requiring hard constraints satisfaction is insufficient."
In summary, penalty methods apply forces orthogonal to the manifold but do not guarantee tangential consistency. As a result, the optimizer oscillates near the manifold without converging to it.
The ideas above are implemented in a Colab notebook, where I compare penalty-based training against a Lagrangian formulation on a constrained toy problem. The code is intentionally separated to keep the focus here on geometry and intuition. View the Colab notebook
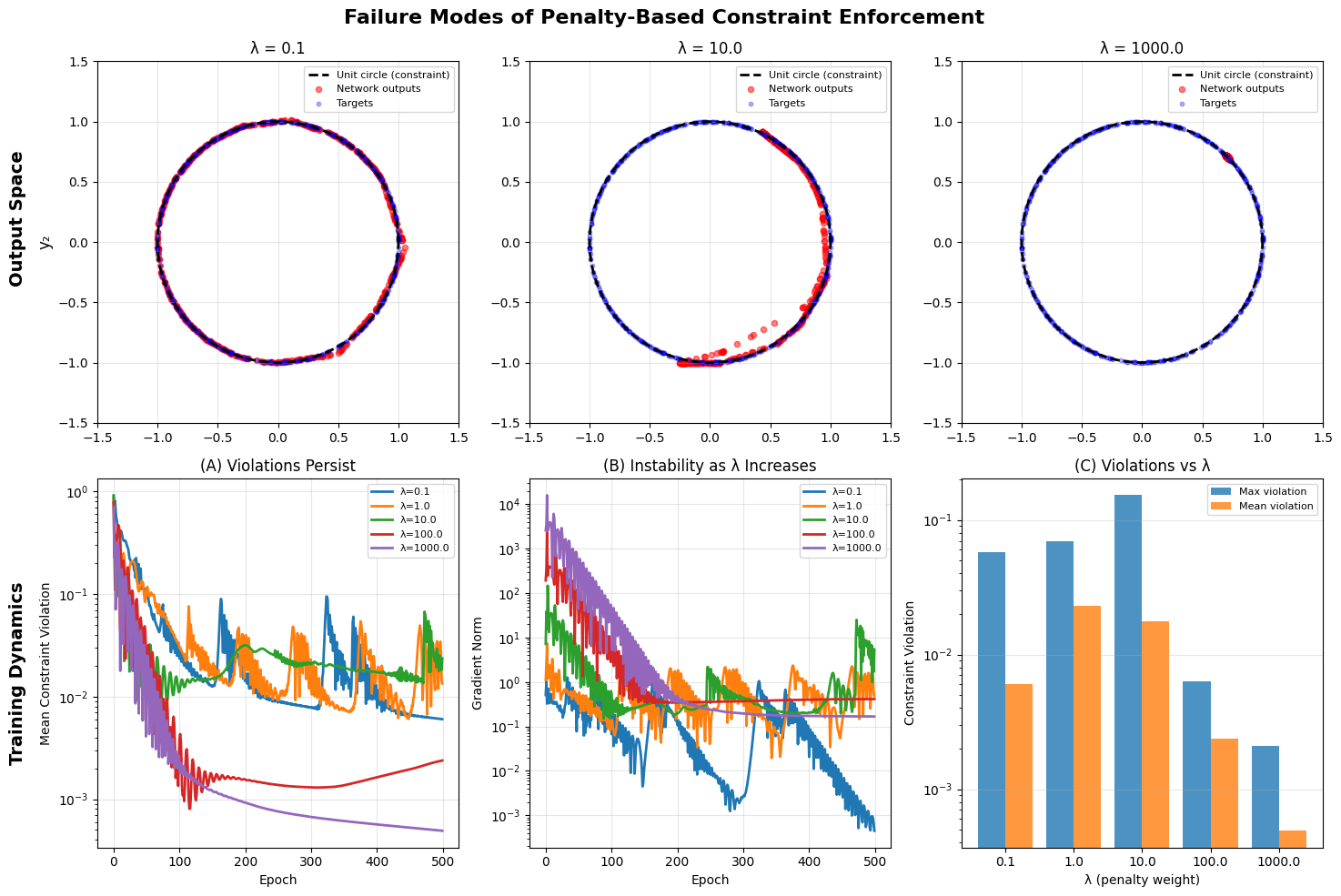 Figure 1: The constraint manifold in output space
Figure 1: The constraint manifold in output space
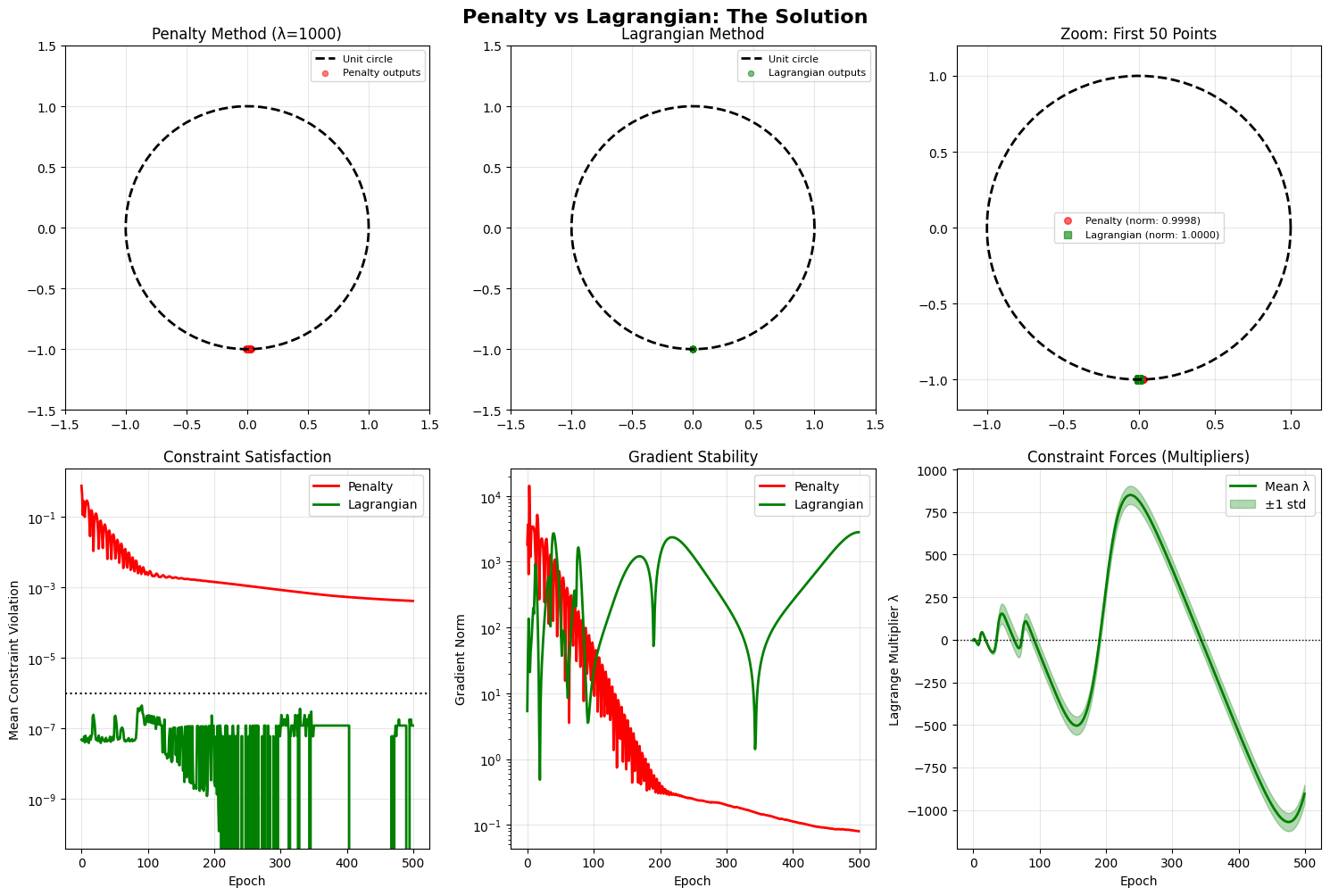
The Lagrangian
The penalty method encourages a neural network to stay close to the constraint manifold by punishing violations. However, this approach treats constraints as soft preferences. To enforce constraints more structurally, we introduce the Lagrangian formulation.
Suppose we want to minimize an objective function subject to a constraint . Instead of optimizing under an explicit restriction, we combine the objective and the constraint into a single function called the Lagrangian.
Formally, the Lagrangian is defined as:
Here:
- y represents the model output or decision variable
- is the constraint
- is the Lagrange multiplier, which controls how strongly the constraint is enforced
Intuitively, the Lagrange multiplier acts like a learnable force that pushes solutions back onto the constraint manifold whenever they drift away.
Lagrangian Formulation
The correct constrained objective is given by the Lagrangian:
Unlike penalty methods, the Lagrangian introduces dual variables that adaptively enforce constraints.
The update then becomes
This defines a primal-dual dynamical system
Why this matters for neural networks?
Neural networks naturally operate in unconstrained spaces. The Lagrangian formulation provides a principled way to introduce constraints without collapsing optimization stability, allowing gradients to respect the geometry of the feasible manifold.
To see the effect of the lagrangian and how the results differ in comparison to the penalty method, you can take a look at the colab code attached below.
Conclusion
Hard constraints are not just additional loss terms or penalties to be tuned; they define geometry.
When a task demands exact satisfaction of constraints, the correct outputs live on a manifold - a thin, structured subset of the output space. Standard neural networks, trained with unconstrained optimization, have no inherent reason to remain on this manifold. They wander near it, approximate it, and often violate it.
Penalty methods attempt to push solutions toward feasibility, while Lagrangian formulations explicitly encode the geometry of the constraint surface. Both approaches acknowledge a fundamental truth: constrained learning is not just about minimizing error, but about respecting structure.
Understanding this distinction reframes the problem. Neural networks do not fail because they are weak function approximators, but because they are trained in spaces larger than the problem allows.
Once we see constraints as geometry, the path forward becomes clearer